


We’ve all been hit with networking jargon since the day we started learning software engineering. From client-server architecture, TCP handshakes, different layers of a network, to a dozen different protocols associated with them, we’ve heard it all. We’ve also nodded along when someone called REST or GraphQL a “protocol“ (spoiler: they’re not), or pretended we fully got how gRPC works.
But if you are like me, you don’t really feel like you understand something until you can picture it from the ground up. You don’t get that confidence until you can image where each of those things live and how they work.
So in this series, we’re going to build these concepts from the ground up. Most of us have a high-level overview of some of them (and it’s okay if you don’t), but to really own the knowledge, we’ll explore each level step-by-step.
Instead of a top-down tour, we’ll be taking a bottom-up approach. We’ll only cover the most relevant concepts for a typical Software Engineer. So, if you’re a Network Engineer, then you might want to learn even lower level things like how two adjacent nodes exchange frames at Layer 2, which is out of scope for this series.
Overview
In this article, we would be covering some basics and key terminology, that will help us understand higher-level things in future articles.
What is Client-Server Architecture?
We all know that in a network of computers (like the Internet), computers can share data and resources with each other.
But which computer is the one sharing the data, and which is the one receiving it?
In the client-server model, the computer making the request for data is called a client, and the computer “serving“ that request is called a server. Most of the web applications you use daily follow this model.
Example:
Let’s walk through how you might interact with a site like Facebook:
First, you connect your computer to the internet.
Your computer (somehow) figures out how to send data to one of Facebook’s computers connected to the internet.
You send a request stating “Hey Facebook, can you give me my profile picture?“.
That request (somehow) travels across the Internet to Facebook’s computer, which begins processing it.
It finds the profile picture (probably in its database) and starts sending the picture data back to you.
Once your computer (browser, mobile app, etc) receives the data, it can display the image.
And the interaction is finally complete.
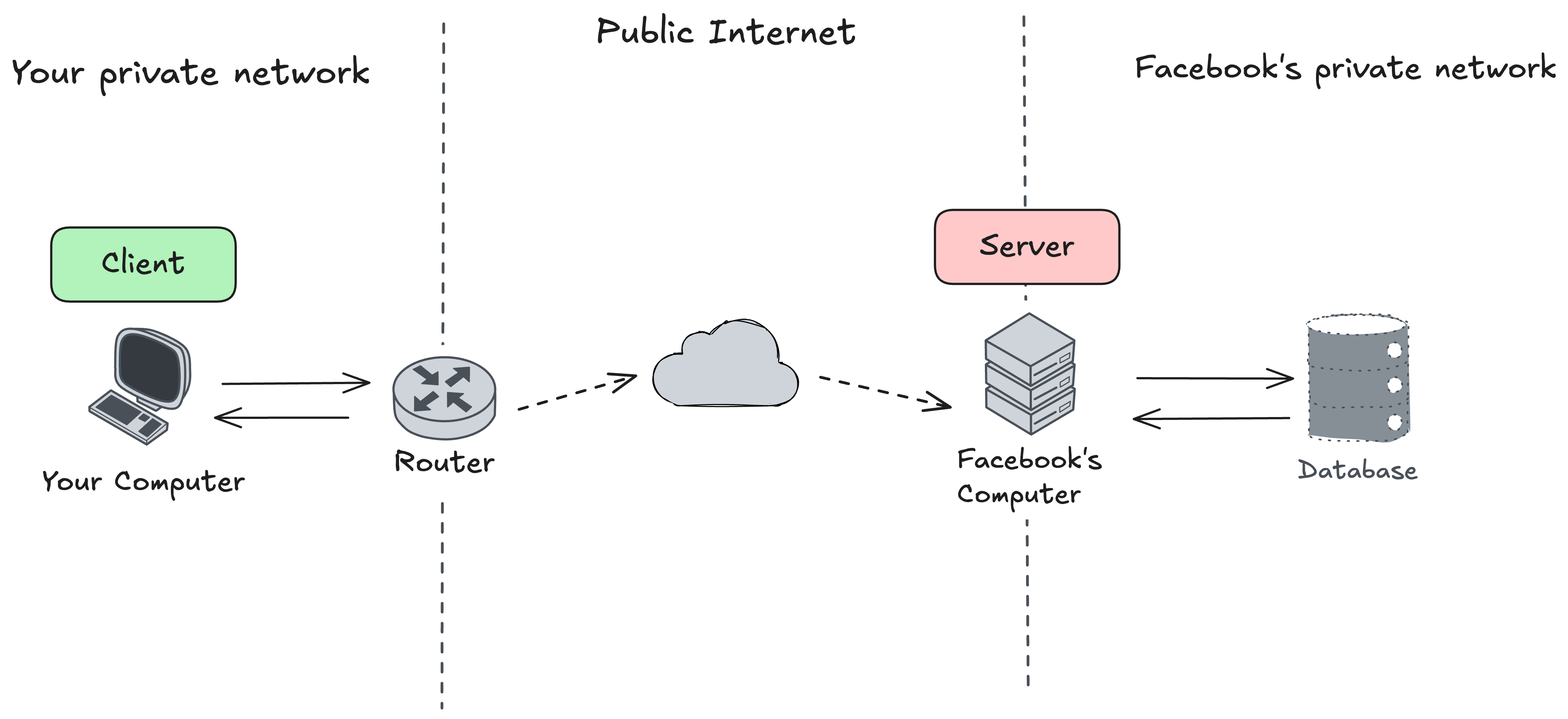
There are a few interesting things happening here:
To get any data from Facebook’s computers, you are the one making a request.
Only then Facebook’s computers serve that request by responding with appropriate data.
This makes your computer a client, and Facebook’s computer a server.
Note: Don’t worry about the “somehow” in the above example - we’ll explore those details in future articles.
Therefore, we come to the following definitions:
A client is a computer (or a process) that makes a request of some kind. It might ask for some data, or request to perform an operation such as uploading or deleting information.
A server is a computer (or a process) that serves those requests. It performs the operation that client has requested, and responds with appropriate data.
Most websites and applications, at their core, do two things:
Manage some data, called the state.
Expose ways for clients to interact with and/or transform that state.
Client and Server are just roles
This is where many people get confused at first.
A client and a server aren’t fixed machines, they are roles that machines (or processes) take in a particular interaction. A machine isn’t always a client or a server.
For example: Facebook’s web servers (the ones that serve your request), might request data from a database to send it back to you. In that interaction, the database is the server (a “DB server”), and the Facebook web server is acting as a client.
Also, the term “server” is used a bit loosely. A server can refer to the actual process that handles a request, the machine that is running that process, or when talking casually about public services, the whole set of machines of an application (like Facebook’s servers).
Network Layers
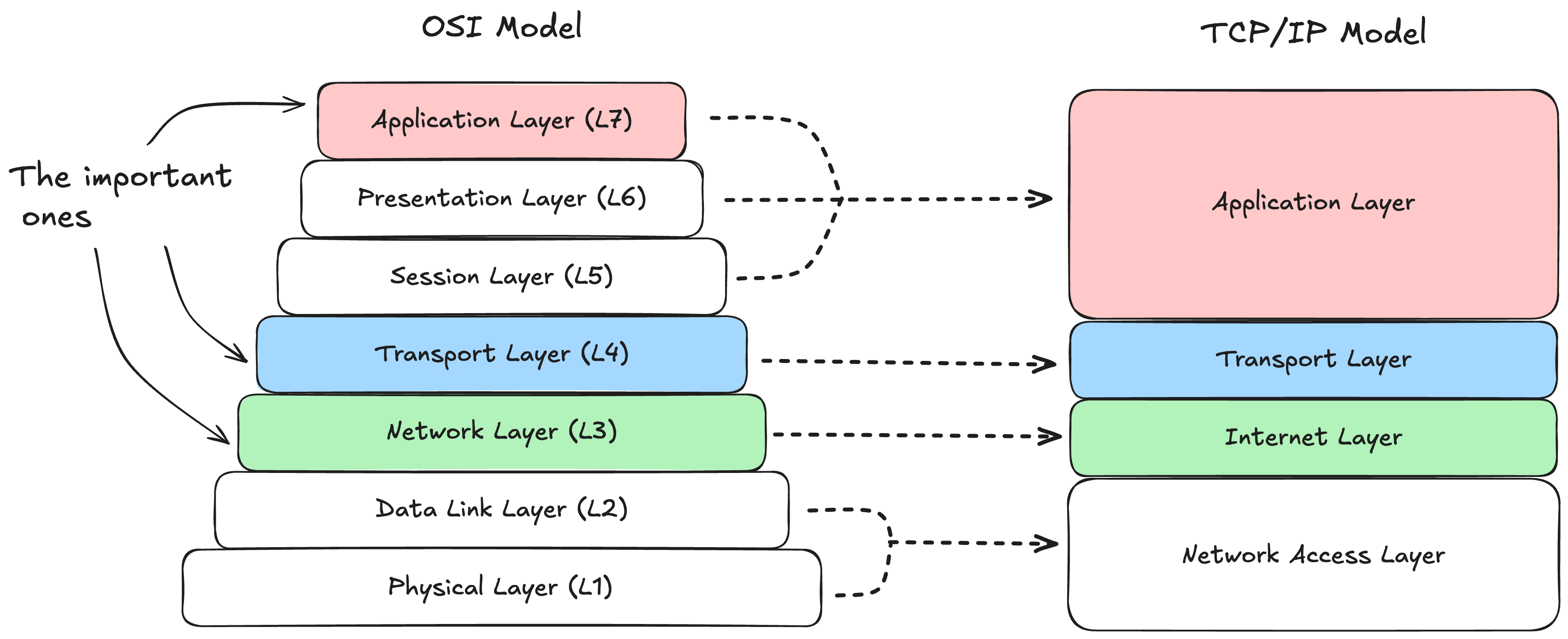
Almost all of you have probably learned, or at least heard about, the layered architecture of networks. The layers of the famous “OSI model“ that we all studied (or at least pretended to) in our universities. But did you know that the Internet doesn’t strictly follow the OSI model? It more closely follows the Internet protocol suite, also called TCP/IP.
If you want to read about the history between the two, check out “OSI: The Internet That Wasn't”.
The OSI model consists of 7 conceptual layers, each with a different purpose. Each layer provides an abstraction that the next layer builds upon. This makes life easier for us developers: while building an application that requests some data, we don’t need to know how voltages represent 1s and 0s on a network wire. We just need to know how to use the next layer down the stack.
While it’s good to know about each layer in the model, we’ll focus on the three most relevant ones that every backend engineer should know. We’ll also see how these three layers map to the TCP/IP model.
For now, we’ll look at an overview of each layer. Later, we’ll have dedicated articles on each and discuss the most important protocols they contain.
But before we dive into layers, let’s get clear on what a protocol is.
What is a Protocol?
A protocol is a set of established rules that dictates how something should be done.
A communication protocol is a set of rules that two or more entities agree upon for how communication should happen.
Protocols exist in our daily lives. For example, try to write down the “unsaid protocol“ in a situation like giving an interview.
There are usually multiple layers of protocols in place. Some of the rules you might come up with:
You greet an interviewer, and the interviewer (hopefully) greets you back - establishing communicating.
By the nature of an interview, you’ve agreed that the interviewer will ask questions one by one, and you’ll answer them.
You’ve also agreed to use a particular language (like English).
And many more rules like that.
Humans are better at inferring protocols based on context (though we still make mistakes and cause awkwardness).
Computers, however, need clear and precise rules. We define standard communication protocols and implement them in machines, so they can understand and talk to each other.
Different protocols cover different responsibilities. From deciding how to route a packet to the right machine, to defining what should happen when a complete request is received.
Layers of the Internet
The following diagram shows the layers in the OSI model, and how they roughly map to the Internet protocol suite (TCP/IP).
Note: While the internet is more aligned with the TCP/IP model, in casual discussion people still OSI numbering. For example: you’ll hear about L4/L7 load balancers, which live at Layer 4 or Layer 7 of the OSI model.
Network Layer (L3) / Internet Layer
In the OSI model, the Network layer is responsible for transferring data packets from a source machine to a destination machine via one or more networks.
In the Internet protocol suite, the roughly analogous layer is the Internet Layer. Here we find the Internet Protocol (or IP), which handles routing and addressing. It breaks the data into packets, forwards them between networks, and provides best-effort delivery to any destination IP address.
Every device that talks on the Internet must follow the Internet Protocol. It’s built into the networking stack of operating systems and routers. This code is what allows those systems to create, read, and forward IP packets.
If you read the RFC 1122, section 1.1.3, under the Internet Layer you’ll find some very interesting things.
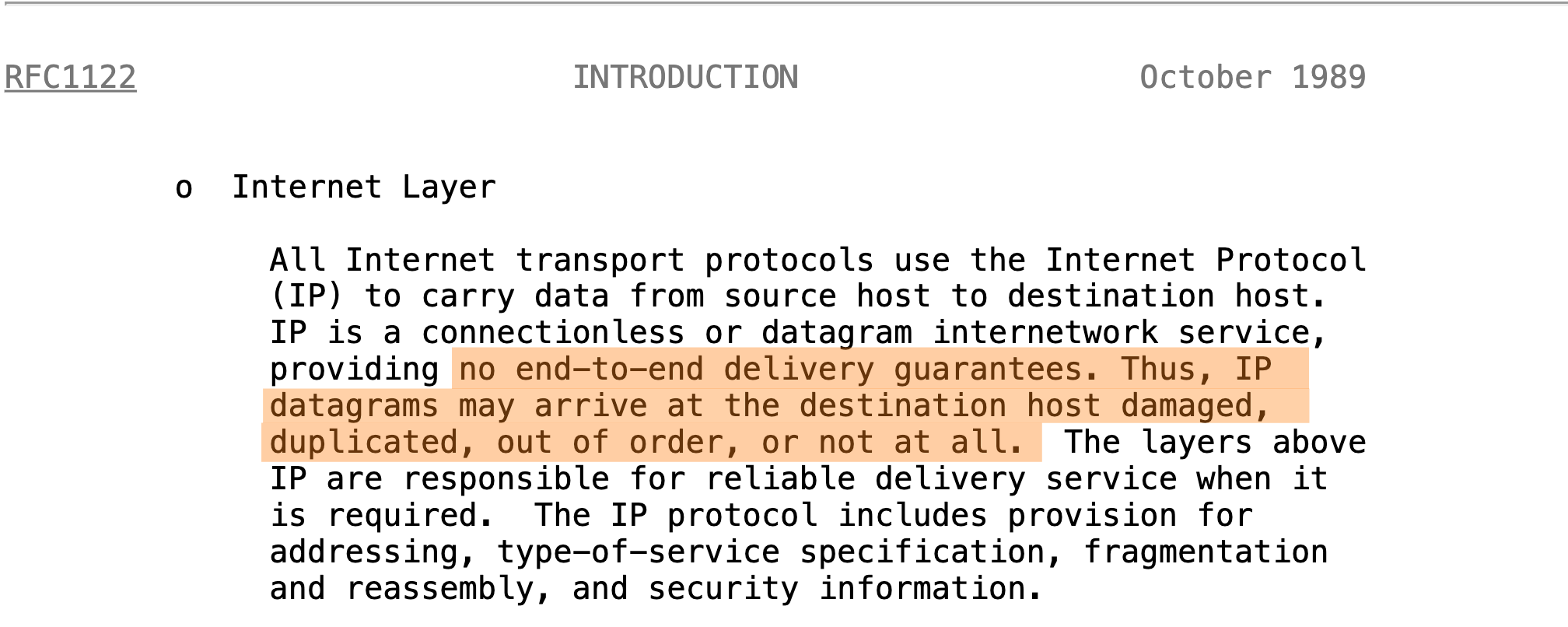
Data packets transferred on the Internet Layer may:
be damaged when they arrive at the destination,
be duplicated and delivered multiple times,
arrive out of order,
or not arrive at all
This doesn’t sound so good. Imagine sending raw text like this:
Please, do NOT press the nuclear button.
And if some packets drop during transmission, the final message might arrive as:
Please press the nuclear button.
Disastrous, to say the least.
This demonstrates that the Internet Protocol in the protocol suite is inherently unreliable. Therefore, we must add reliability on at higher layers.
Transport Layer (L4)
The Transport Layer is built on top of the Internet Layer (or Network Layer in OSI) to provide more features. At this layer, we have TCP, UDP, and QUIC, which provide end-to-end communication services.
The Internet Layer only ensures that data reaches the right machine. But the destination machine might have multiple applications or processes running, so how do we decide which application the data goes to?
That’s one of the key responsibilities of the Transport Layer. It uses port numbers to decide which application on the destination machine should receive the data.
The two primary protocols you should focus on for now are:
TCP (Transmission Control Protocol): provides features like reliability, ordering, and flow control on top of the internet layer. That means your packets will (almost) always arrive, in order, and without corruption.
UDP (User Datagram Protocol): provides a lightweight, connectionless way to send datagrams. It does not guarantee delivery, ordering, or reliability.
We’ll see how TCP and UDP add more features on top of IP in future articles. For now, you can treat them as black boxes that provide extra features the Internet Layer cannot.
TCP and UDP are baked into the operating system’s networking stack. Your programs just call the socket APIs, and the OS handles the rest.
QUIC is a modern transport control protocol built by Google on top of UDP. It provides reliability, encryption, and multiplexing similar to TCP, but with faster connection setup. It operates in user space, unlike TCP and UDP, which primarily operate in kernel space. For now, you’re less likely to bump into QUIC directly - most of the time you’ll be dealing with TCP or UDP.
Application Layer (L7)
Finally, the layer we mere mortals usually live in.
The Application Layer is the top layer of the Internet protocol suite (and also the OSI model). At this layer you’ll find the application protocols like DNS, HTTP, WebSocket, WebRTC, and more.
This is also the layer where the concept of client-server exists, since that’s an application-level concept. The layers below don’t care about client-server; they can just as easily support peer-to-peer applications.
A few common protocols are:
DNS (Domain Name System): translates human-readable names like
facebook.cominto IP addresses that computers use to connect to the right machine.HTTP (HyperText Transfer Protocol): defines how clients and servers exchange requests and responses for web pages and APIs.
WebSocket: enables persistent, two-way communication between client and server. Used in chat applications, notifications, and real-time updates.
WebRTC (Web Real-Time Communication): a set of protocols and APIs that enable peer-to-peer audio, video, and data sharing directly between devices.
This is the layer where our application code lives, handling request-response cycles. For example: the HTML/CSS/JS loaded in the browser on the client side, and the backend server (written in Go, Java, etc) both operate at this layer. The client side knows how to make requests, and the server side knows how to handle requests and send back responses.
How data flows between different layers?
Each layer only knows how to talk to the layer above and below it. Therefore, a request might look something like this:
Application Layer (L7): The application prepares an HTTP request (e.g., “give me my profile picture”), and hands it down to the Transport Layer.
Transport Layer (L4): breaks the request into smaller chunks, adds information so they can be reassembled correctly, and tags the data with the port number of the application it’s meant for.
Internet Layer (L3): Adds the source and destination IP addresses so the data knows where it’s coming from and where it should go.
Network Access Layer (L2/L1): Converts the data into frames and bits and physically transmits them across the network.
On the receiving end, the process happens in reverse: each layer strips away its own wrapper until the HTTP request finally reaches the application.
Conclusion
Phew, that was quite an introduction. Networking is the foundation that connects all the components of any large system. We didn’t dive into the nitty-gritty of each protocol here - the goal was to give you a mental model of how everything fits together.
In the next set of articles, we’ll zoom into each of these layers, explore the protocols in more depth, and discover some new concepts along the way. You can find referred resources here:
Until then, have fun and keep learning!